Efficiently Reducing Storage Footprint in Reproducible Containers via I/O Specialization
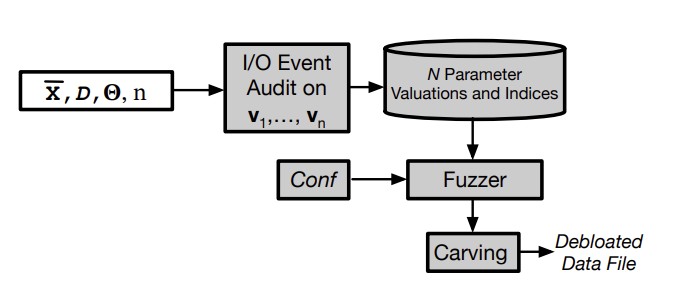
Isolation increases upfront costs of provisioning containers. This is due to unnecessary software and data in container images. While several static and dynamic analysis methods for pruning unnecessary software are known, less attention has been paid to pruning unnecessary data. In this paper, we address the problem of determining and reducing unused data within a containerized application. Current data lineage methods can be used to detect data files that are never accessed in any of the observed runs, but this leads to a pessimistic amount of debloating. It is our observation that while an application may access a data file, it often accesses only a small portion of it over all its runs. Based on this observation, we present an approach and a tool Kondo, which aims to identify the set of all possible offsets that could be accessed within the data files over all executions of the application. Kondo works by fuzzing the parameter inputs to the application, and running it on the fuzzed inputs, with vastly fewer runs than brute force execution over all possible parameter valuations. Our evaluation on realistic benchmarks shows that Kondo is able to achieve 63% reduction in data file sizes and 98% recall against the set of all required offsets, on average.
Tikmany, R., Modi, A., Atiq, R., Reyad, M., Gehani, A., and Malik, T.
IEEE Cluster, Cloud and Internet Computing (CCGrid)
2024